CLR-Bench: Evaluating Large Language Models in College-level Reasoning
Junnan Dong, Zijin Hong, Yuanchen Bei, Feiran Huang, Xinrun Wang, Xiao Huang
The Hong Kong Polytechnic University, Jinan University, Singapore Management University
Junnan Dong, Zijin Hong, Yuanchen Bei, Feiran Huang, Xinrun Wang, Xiao Huang
The Hong Kong Polytechnic University, Jinan University, Singapore Management University
Large language models (LLMs) have demonstrated their remarkable performance across various language understanding tasks. While emerging benchmarks have been proposed to evaluate LLMs in various domains such as mathematics and computer science, they merely measure the accuracy in terms of the final prediction on multi-choice questions. However, it remains insufficient to verify the essential understanding of LLMs given a chosen choice.
To fill this gap, we present CLR-Bench to comprehensively evaluate the LLMs in complex college-level reasoning.
📌 we prioritize 16 challenging college disciplines in computer science and artificial intelligence. The dataset contains 1018 questions in 5 types, i.e., Multi-choice (MC), Multi-select (MS), Fill-in-blank (FB), Open-ended (OE), True-or-false (TF), each associated with detailed explanations from experts.
⚖ We formalize the criteria with two novel metrics:
Q→A to measure the performance of direct answer prediction, and Q→AR to evaluate the joint ability to answer and provide rationale simultaneously.
🤔 LLMs are potentially 'guessing' the answers for college-level questions, instead of truly understanding the rationale with a dramatically dropping Q→AR.
🔍 Model sizes do not inherently guarantee superior performance in reasoning, despite larger models often achieving higher accuracy in Q→A. Several smaller models notably exhibit stronger performance in Q→AR, surpassing larger ones to provide accurate and coherent rationales.
| # | Models | Q->A (Direct performance of prediction) | Q->AR (Reasoning performance of rationale) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MC | MS | TF | FB | OE | Q->A | MC | MS | TF | FB | OE | Q->AR | ||
| 1 | qwen2.5-32b-instruct | 80.18 | 75.23 | 63.29 | 44.76 | 52.04 | 63.31 | 55.41 | 45.50 | 56.0 | 48.33 | 11.80 | 42.29 |
| 2 | deepseek-chat | 78.80 | 77.03 | 62.66 | 40.95 | 51.30 | 62.43 | 55.41 | 44.14 | 55.14 | 46.43 | 13.48 | 42.09 |
| 3 | gpt-4o | 84.33 | 76.58 | 63.92 | 54.29 | 34.01 | 60.76 | 53.11 | 44.82 | 57.52 | 51.19 | 8.55 | 41.60 |
| 4 | qwen2.5-72b-instruct | 81.11 | 77.93 | 63.61 | 45.71 | 52.23 | 64.05 | 50.58 | 45.50 | 53.56 | 48.10 | 13.10 | 40.79 |
| 5 | gpt-4-turbo | 82.49 | 78.38 | 63.92 | 50.48 | 45.91 | 63.31 | 51.73 | 45.95 | 49.45 | 51.43 | 8.74 | 39.00 |
| 6 | claude-3-opus | 80.18 | 81.53 | 62.66 | 52.38 | 44.42 | 62.57 | 50.35 | 43.02 | 50.08 | 50.00 | 9.20 | 38.56 |
| 7 | claude-3-sonnet | 76.96 | 76.58 | 59.81 | 42.86 | 48.33 | 60.51 | 50.69 | 44.59 | 48.26 | 45.95 | 11.80 | 38.51 |
| 8 | qwen2.5-72b | 80.18 | 73.42 | 60.44 | 47.62 | 52.04 | 62.52 | 50.00 | 43.02 | 45.97 | 49.52 | 11.99 | 37.89 |
| 9 | phi-3-medium-4k-instruct | 74.65 | 63.96 | 56.01 | 38.10 | 48.88 | 57.12 | 51.50 | 33.56 | 49.68 | 44.05 | 11.34 | 37.60 |
| 10 | qwen2.5-7b-instruct | 70.97 | 63.06 | 58.23 | 37.14 | 49.26 | 56.93 | 52.65 | 34.23 | 50.32 | 41.90 | 8.92 | 37.25 |
| 11 | gemini-1.5-pro | 78.34 | 71.62 | 55.38 | 46.67 | 52.42 | 60.36 | 50.46 | 40.54 | 43.35 | 50.24 | 12.83 | 37.21 |
| 12 | phi-3-mini-4k-instruct | 69.12 | 59.46 | 55.38 | 34.29 | 44.80 | 53.78 | 49.42 | 37.84 | 45.41 | 41.43 | 9.57 | 35.56 |
| 13 | gpt-3.5-turbo | 63.13 | 66.67 | 5854 | 23.81 | 47.77 | 53.98 | 42.51 | 41.22 | 49.60 | 39.29 | 6.41 | 34.70 |
| 14 | gemma2-9b-it | 72.81 | 50.45 | 55.70 | 43.81 | 40.52 | 53.54 | 45.62 | 32.88 | 47.15 | 44.52 | 7.90 | 34.63 |
| 15 | yi-1.5-34b-chat | 68.66 | 53.60 | 56.96 | 40.95 | 39.96 | 52.95 | 40.90 | 33.33 | 48.34 | 44.76 | 7.16 | 33.87 |
| 16 | llama-3.1-70b-instruct | 80.18 | 74.77 | 61.39 | 40.00 | 44.61 | 60.22 | 44.24 | 38.06 | 45.09 | 38.57 | 7.99 | 33.67 |
| 17 | llama-3.1-70b | 75.58 | 51.80 | 5759 | 45.71 | 47.77 | 56.97 | 43.89 | 35.81 | 41.46 | 45.48 | 10.50 | 33.60 |
| 18 | qwen2.5-7b | 69.12 | 54.95 | 54.11 | 40.00 | 49.07 | 54.62 | 43.55 | 34.46 | 43.43 | 45.00 | 8.36 | 33.37 |
| 19 | yi-1.5-34b | 70.97 | 58.11 | 5759 | 41.90 | 48.33 | 56.43 | 40.55 | 35.59 | 42.96 | 43.10 | 7.25 | 32.22 |
| 20 | llama-3-8b-instruct | 60.83 | 49.55 | 52.22 | 29.52 | 47.40 | 50.15 | 43.78 | 26.35 | 41.30 | 36.19 | 9.76 | 31.34 |
| 21 | mixtral-8x7b-instruct-v0.1 | 59.91 | 45.05 | 34.18 | 16.19 | 43.12 | 41.36 | 42.97 | 31.31 | 39.08 | 34.52 | 8.36 | 30.48 |
| 22 | llama-3.1-8b-instruct | 63.13 | 51.80 | 56.96 | 25.71 | 41.82 | 50.49 | 39.06 | 22.97 | 41.85 | 33.57 | 8.55 | 29.54 |
| 23 | mixtral-8x7b-v0.1 | 67.28 | 39.64 | 53.48 | 39.05 | 45.72 | 51.38 | 39.06 | 31.53 | 36.00 | 36.19 | 8.83 | 29.00 |
| 24 | llama-3.2-3b-instruct | 57.14 | 39.19 | 49.05 | 23.81 | 34.94 | 43.37 | 40.55 | 21.40 | 38.29 | 32.62 | 8.09 | 28.36 |
| 25 | yi-1.5-6b | 53.00 | 59.01 | 51.27 | 30.48 | 42.75 | 48.08 | 33.53 | 29.95 | 39.16 | 35.00 | 6.13 | 27.80 |
| 26 | qwen1.5-7b | 58.99 | 54.50 | 47.15 | 37.14 | 38.29 | 47.10 | 36.64 | 33.11 | 32.99 | 35.95 | 6.78 | 27.16 |
| 27 | mistral-7b-v0.1 | 58.06 | 42.79 | 50.63 | 37.14 | 43.87 | 48.18 | 33.06 | 29.05 | 34.10 | 35.24 | 7.16 | 26.33 |
| 28 | mistral-7b-instruct-v0.1 | 57.60 | 45.05 | 40.82 | 21.90 | 42.19 | 43.27 | 35.48 | 27.48 | 34.41 | 33.33 | 6.04 | 26.28 |
| 29.0 | llama-3.1-8b | 62.67 | 40.54 | 5158 | 30.48 | 44.98 | 48.82 | 34.22 | 28.83 | 32.52 | 33.57 | 7.99 | 26.11 |
| 30 | openchat-3.5 | 60.83 | 39.64 | 49.68 | 25.71 | 36.25 | 44.94 | 35.94 | 22.75 | 33.86 | 30.24 | 8.46 | 26.01 |
| 31 | yi-1.5-6b-chat | 37.33 | 53.15 | 48.10 | 25.71 | 38.85 | 41.60 | 30.30 | 32.43 | 32.99 | 34.05 | 6.88 | 25.56 |
| 32 | llama-3-8b | 59.91 | 35.14 | 50.95 | 26.67 | 43.31 | 46.61 | 32.37 | 24.10 | 31.09 | 29.29 | 7.53 | 24.19 |
| 33 | deepseek-7b-chat | 49.31 | 27.48 | 45.57 | 20.00 | 31.41 | 38.02 | 30.76 | 18.92 | 34.97 | 27.62 | 5.11 | 23.67 |
| 34 | qwen1.5-7b-chat | 32.26 | 50.00 | 11.71 | 13.33 | 35.32 | 26.67 | 27.42 | 26.58 | 27.22 | 33.57 | 6.41 | 22.35 |
| 35 | llama-2-7b-chat | 38.25 | 36.49 | 39.24 | 13.33 | 35.50 | 35.07 | 26.04 | 16.89 | 31.49 | 26.67 | 5.30 | 21.32 |
| 36 | deepseek-7b-base | 49.77 | 36.49 | 44.94 | 18.10 | 36.62 | 40.08 | 27.88 | 18.47 | 28.16 | 25.24 | 5.39 | 20.73 |
| 37 | llama-2-7b | 54.38 | 15.77 | 44.62 | 19.05 | 36.43 | 38.75 | 26.61 | 18.47 | 27.29 | 24.05 | 6.78 | 20.43 |
| 38 | llama-3.2-1b-instruct | 41.47 | 40.99 | 37.66 | 14.29 | 25.09 | 33.10 | 28.00 | 13.06 | 24.68 | 24.76 | 6.69 | 19.38 |
| 39 | gemma-7b-it | 15.21 | 37.84 | 45.25 | 8.57 | 13.38 | 25.83 | 13.02 | 1.80 | 35.52 | 20.24 | 10.04 | 18.74 |
| 40 | gemma2-9b | 16.13 | 47.75 | 11.71 | 9.52 | 11.34 | 16.26 | 11.29 | 8.33 | 10.60 | 11.67 | 3.62 | 8.77 |
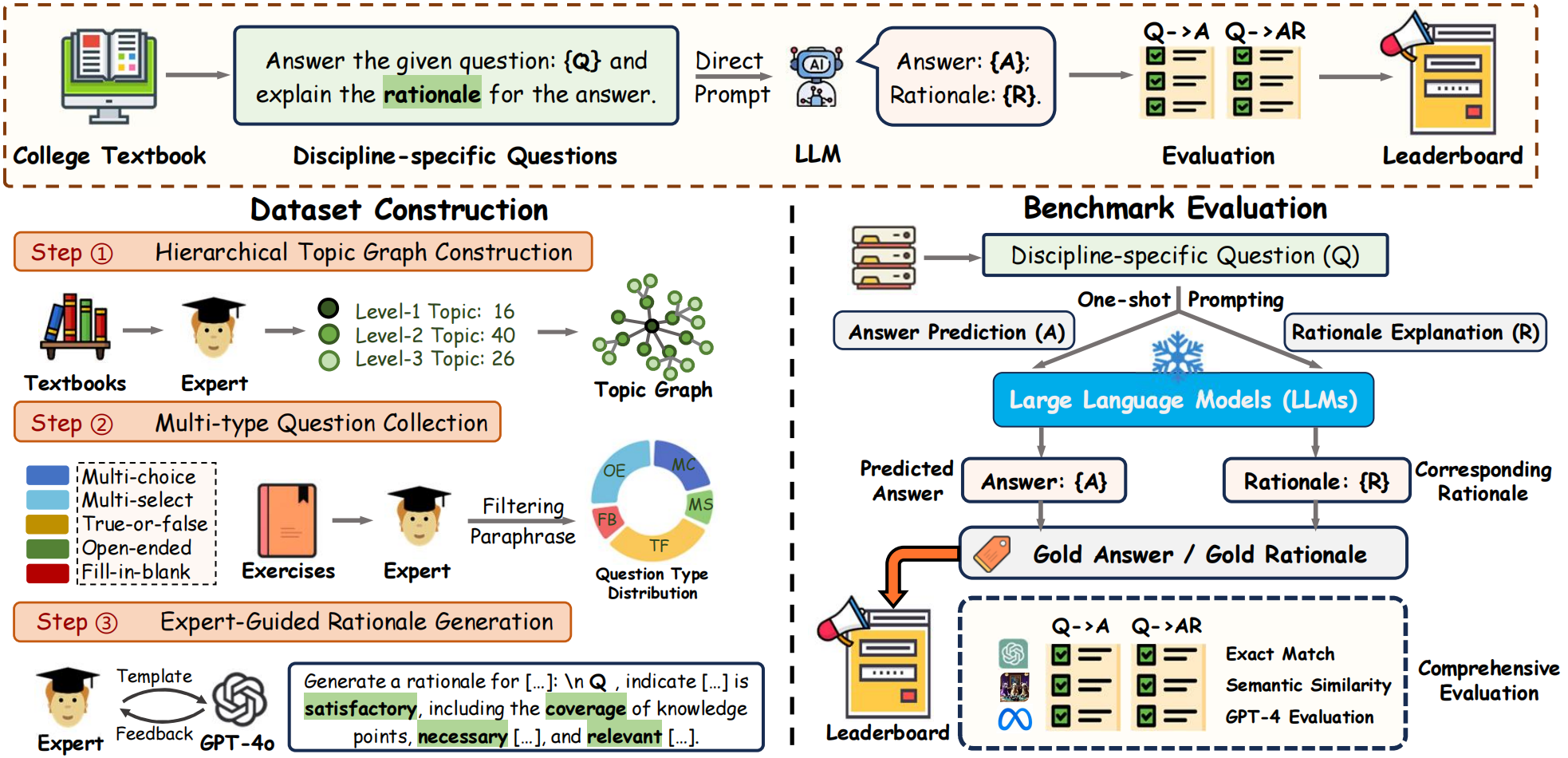
The overview of our proposed CLR-Bench. Dataset Construction. Domain experts first curate a condensed hierarchical topic graph to guide the collection of five types of questions. GPT-4o is then carefully instructed to assist the experts in gold rationale generation. Benchmark Evaluation. We formally define standardized criteria for each type of question and the corresponding rationale.
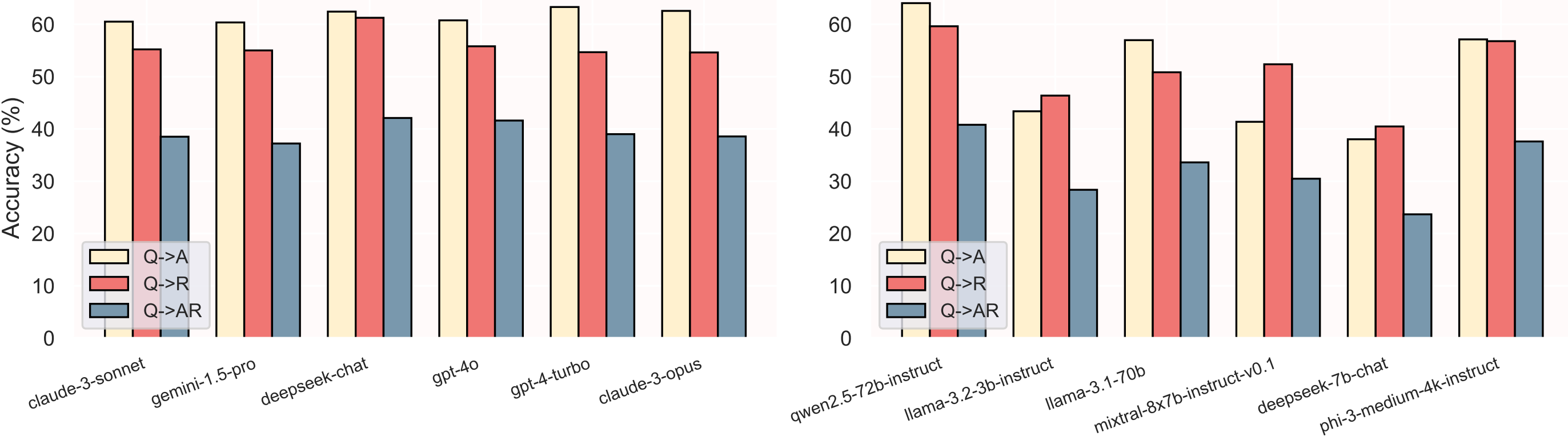
LLMs tend to ‘guess’ answers.
A detailed analysis of Q→AR scores reveals that despite their relatively high accuracy in answering questions (Q→A), many LLMs struggle significantly to provide coherent and accurate rationales.
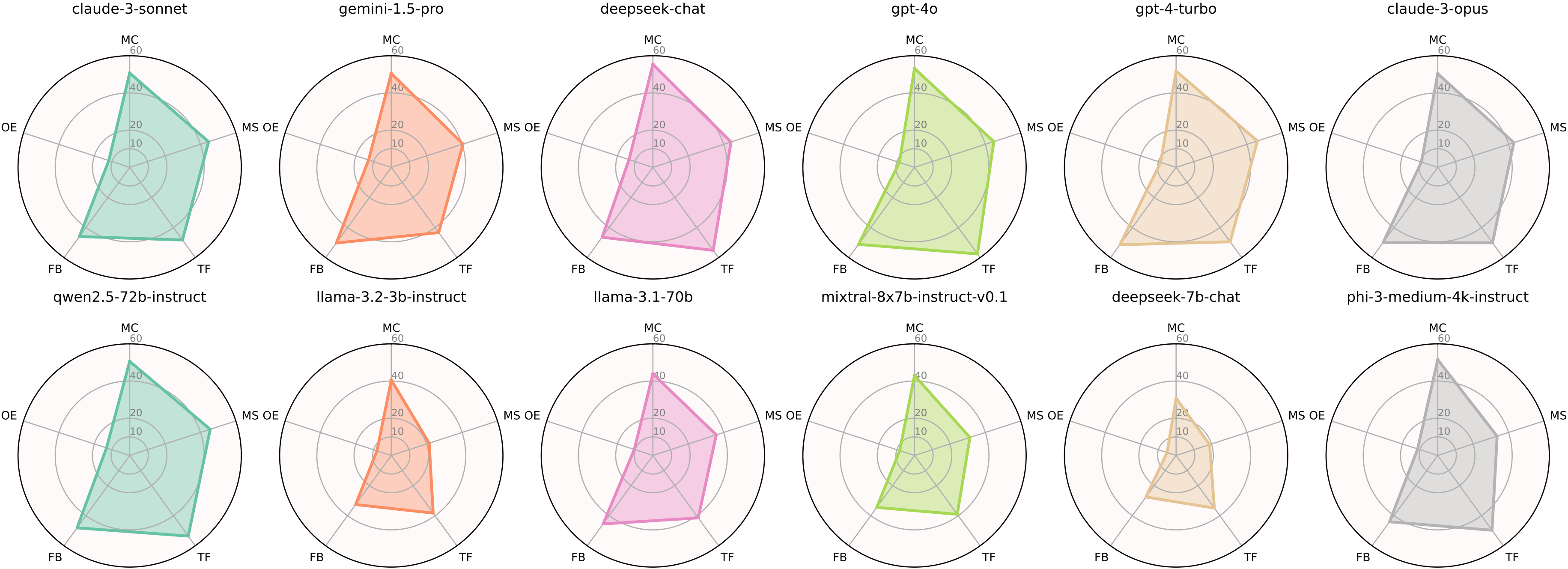
LLMs are not good at non-MC questions.
We visualize the radar diagrams to showcase the expertise of LLMs on different types of questions. Performance on non-MC questions presents another significant challenge for LLMs. Many models demonstrate reasonable performance on MC, yet their accuracy drops significantly when handling OE or FB questions, which require deeper reasoning and articulation.
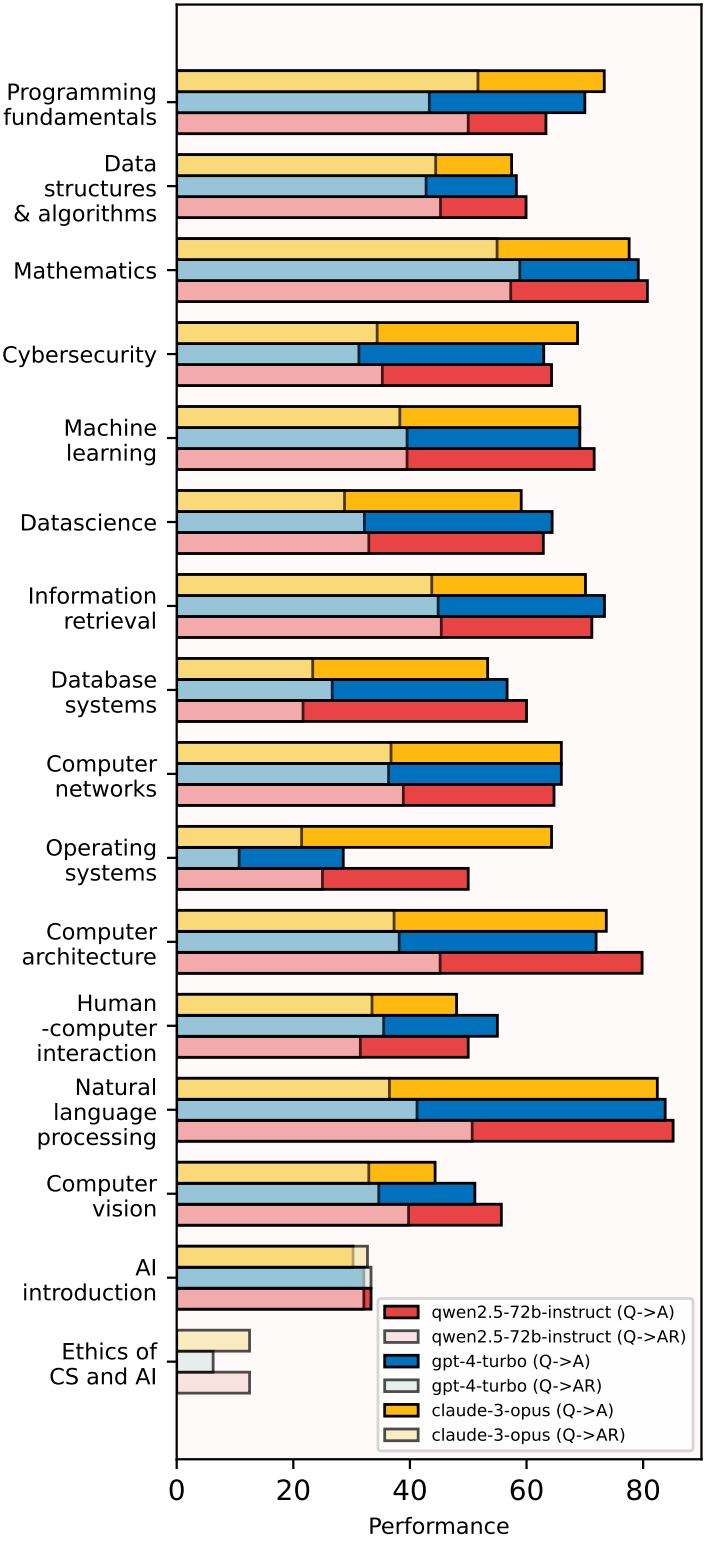
Discipline-specific insights
\((i)\) Context-intensive tasks. Topics such as AI Introduction and Ethics of CS and AI require a solid understanding of conceptual frameworks. All three state-of-the-art LLMs demonstrate a surprisingly low performance with around 12.5% and 6.5% Q→AR. This suggests challenges in grasping nuanced ethical considerations. Similarly, scores in the AI Introduction domain reflect the models’ difficulty in conveying complex ideas coherently. These results highlight that while LLMs possess substantial factual knowledge, they often struggle with articulating and rationalizing that knowledge in contextually rich environments.
\((ii)\) Reasoning-intensive tasks. Mathematics and Computer Architecture reflect a different situation compared with context-intensive tasks. All three models could perform significantly satisfying the Q→A criteria; however, their performance decreases sharply on Q→AR with over a 30% accuracy drop in average. This reflects the necessity for improved training techniques that focus on fostering deeper cognition for reasoning-intensive tasks.
For inquiries or contributions, please contact us at hanson.dong@connect.polyu.hk.